大數據架構下的數據處理服務與業務處理流程解析
隨著數字化轉型的深入,大數據已成為企業核心競爭力的關鍵要素。高效、可靠的大數據架構與業務處理流程,是支撐數據驅動決策的基礎。本文旨在解析大數據架構的核心組件,并闡述數據處理服務在業務處理流程中的關鍵作用。
一、 大數據架構的核心層析
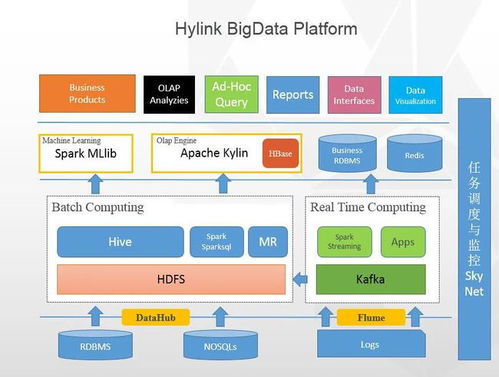
一個典型的大數據架構通常由數據源層、數據采集與存儲層、數據處理與分析層、數據服務與應用層構成。
- 數據源層:這是數據的起點,包括企業內部的關系型數據庫、日志文件、應用API,以及外部的物聯網傳感器數據、社交媒體流、第三方數據等。數據格式多樣,涵蓋結構化、半結構化和非結構化數據。
- 數據采集與存儲層:此層負責從源頭高效、穩定地攝取數據。常用工具如Apache Kafka、Flume用于實時流數據采集,Sqoop用于關系型數據庫批量導入。采集后的數據存入分布式存儲系統,如Hadoop HDFS提供高容錯性的廉價存儲,或云上的對象存儲(如AWS S3)。為了支持快速查詢,數據也可能被導入數據倉庫(如Snowflake、Redshift)或數據湖(如基于Hudi、Iceberg的湖倉一體架構)。
- 數據處理與分析層:這是架構的“引擎”所在。數據處理服務在此層大顯身手:
- 批量處理:針對歷史海量數據,使用如Apache Spark、MapReduce等框架進行復雜的ETL(抽取、轉換、加載)操作、數據清洗和聚合計算。
- 流式處理:針對實時數據流,使用如Apache Flink、Spark Streaming等框架進行實時過濾、聚合、關聯分析,實現低延遲的洞察。
- 交互式查詢:利用Presto、Impala等引擎,對存儲在HDFS或數據湖中的數據執行亞秒級到秒級的快速即席查詢。
- 數據服務與應用層:將處理后的數據轉化為業務價值。通過數據API、可視化報表(如Tableau、Superset)、機器學習模型服務、推薦系統等形式,直接服務于業務用戶、決策者或下游應用系統。
二、 數據處理服務:業務流程的賦能者
數據處理服務并非孤立存在,而是深度嵌入業務處理流程的每一個關鍵環節,驅動流程自動化與智能化。
1. 流程起點:實時感知與采集
在業務流程觸發時(如用戶點擊、交易發生、設備上報),數據處理服務(如Kafka流)實時捕獲事件數據,確保業務活動的“足跡”被完整、即時地記錄,為后續分析提供鮮活的素材。
2. 流程核心:決策支持與自動化
這是數據處理服務創造價值的關鍵階段:
- 實時風控:在支付或信貸流程中,流處理服務實時分析交易模式,毫秒內識別欺詐行為并觸發攔截。
- 個性化推薦:在電商瀏覽或內容消費流程中,系統基于用戶實時行為和歷史數據,通過模型計算即時生成并更新推薦列表。
- 運營監控:對供應鏈、生產線等業務流程,服務實時聚合設備狀態、訂單進度等指標,異常發生時立即告警。
- 批量報表與洞察:日終或定期,批量處理服務運行復雜的業務邏輯,生成銷售報表、用戶分群、財務核算等結果,支持次日業務復盤與戰略規劃。
3. 流程優化:閉環反饋與學習
數據處理服務將應用層產生的業務效果數據(如推薦點擊率、營銷轉化率)再次收集、分析,用于評估和優化模型與策略,形成一個“數據驅動決策 -> 行動 -> 效果評估 -> 優化”的持續改進閉環,使得業務流程本身具備學習與進化能力。
三、 關鍵考量與未來趨勢
構建高效的數據處理服務與流程需關注:可擴展性以應對數據量增長;低延遲以滿足實時業務需求;端到端的數據質量與一致性保障信任;以及強大的運維監控能力確保服務穩定。
隨著云原生、存算分離、流批一體技術的成熟,大數據架構正朝著更彈性、更經濟、更簡化的方向發展。DataOps和MLOps理念的普及,正促使數據處理服務與業務處理流程更緊密地融合,實現從數據到業務價值的更高效、更自動化轉化。
一個設計精良的大數據架構及其上的數據處理服務,是現代企業業務處理流程的“數字神經系統”。它不僅被動地記錄業務,更主動地感知、分析、預測并驅動業務行動,成為企業智能化轉型的核心支柱。
如若轉載,請注明出處:http://www.51face.cn/product/13.html
更新時間:2026-05-23 08:22:36